I have a HP EliteBook laptop that caused me a bit of head-scratching today. The inbuilt display had become quite bright, with low contrast, and was difficult to see unless I was directly in front of the display. Adjusting the brightness down made things worse as the contrast became very low. Looking at the screen, it was as though my glasses had fogged over.
I started trawling through all the possible Windows settings for the display, color profile settings, color calibration wizard, as well as the Intel graphics control panel settings. None of this improved matters. Googling for an answer didn’t help as it only suggested things I’d already tried. I was just about to conclude that the display had some kind of hardware failure, when I noticed an icon on the F2 key (next to the brightness down/up keys) that I didn’t recognise. What does that key do??
On clicking the button, the display is back to normal. Hurray!
Unknown to me before now, that button toggles the HP Sure View feature, which is supposed to be a privacy guard feature that makes the display hard to read by someone sitting beside you. (I say ‘supposed to be’ because it makes the screen so irritating to look at that users will quickly switch it off again.)
It was somewhat annoying to discover that what is supposed to be a feature, when activated accidentally is indistinguishable from a hardware failure. What would have been better if HP had done something like what Microsoft does with their Sticky Keys feature, where if you accidentally try to activate it (by pressing the Shift Key 5 times) it
Explains the feature.
Gives you the option to enable it, or cancel.
Tells you how to disable the warning in future, if that’s what you’d like to do.
A good example of how to handle accidental activation of a hidden feature.
I’ve just finished reading the excellent book “The AI Con” by Emily M Bender and Alex Hanna. I was made aware of the book when David Marr interviewed Emily on the Late Night Live radio show on 3 July 2025. The book eloquently and powerfully, with much considered insight, and with doses of humour, exposes the vacuous and dangerous hype of AI promoters.
The book analyses many egregious claims, and one that particularly resonated with me is the way big tech positions AI as the authoritative information source … you ask a question and you get back the answer. Bender and Hanna describe this as the fantasy of “frictionless” access. (I have edited the text below slightly so that it reads more fluently as a stand-alone quote.)
Many of the proposed use cases of Large Language Models (LLMs) are as information access systems, often as a direct replacement for search engines. This uses case trades on a long standing fantasy of making information access “frictionless”: you type in your question and you get the answer. But text synthesis machines are a terrible match for this use case, on two levels. 1. They are inherently unreliable and inclined to make s**t up. 2. Friction in information access is not only beneficial, but critically important.
“The AI COn”, Emily M BEnder and Alex Hanna, 2025. paGE 171.
The point here is that learning is not the simplistic “ask a question, get an answer” model that AI chatbots espouse. Learning involves asking questions, getting multiple answers, evaluating the answers, comparing and contrasting the answers, rating the authority of the answers, identifying gaps in the answers, refining our understanding so that we can ask follow-up questions. AI systems in their mode of presenting “the answer” devalues, demotes, and dissuades the very essential human components required for authentic information enquiry – analysis, comparison, evaluation, reflection etc.
Take for example Google’s “AI Overview” that they have unhelpfully foisted upon us all with no way to disable. Recently I had an occasion where my laptop rebooted overnight after a Windows Update and I lost the set of web pages open in my browser while doing ongoing research. No big deal, but just a bit annoying. Let’s ask Google “How to disable automatic restart in Windows 10”.
The AI Overview is then confidently presented as the authoritative answer in 4 ways …
Positioned at the top of the page
With an icon
In large font
With the instructions highlighted
The answer is in the AI Overview is a correct answer, but it is not the answer to the question I was wanting answered. The AI Overview answer provided instructions on how to prevent an automatic restart after a system failure, whereas I was wanting to know about preventing an automatic restart after a Windows Update. The list of conventional Google search results quickly reveals (by the use of human intelligence) that my question covered a number of scenarios and that I need to refine my question. The AI Overview taking up considerable space at the top of the page was a prominent impediment to getting to the actual information I was seeking.
Clearly AI Overview performs badly when presented with questions that are ambiguous, or where there are multiple legitimate answers. But even for questions where there is no ambiguity, AI Overview’s results are egregiously bad. Take the example of postcodes used in mailing addresses. In Australia each 4 digit postcode is associated with one or more suburb/town names. There is a canonical and unambiguous correlation of postcodes to suburb/town names maintained by Australia Post. How does AI Overview fare in this space? Let’s try “What is the postcode for Lambton?”
Full marks to the system for using location information to know that I am asking about “Lambton, NSW, Australia” and not “Lambton, Quebec, Canada”, and the answer of 2299 is correct, and the comment that “this also applies to North Lambton” is also correct. But the answer omits the information that 2299 is also the postcode for Jesmond. So while the AI Overview answer is correct, it only provides two-thirds of the relevant information about postcode 2299 while presenting itself as the authoritative answer.
It gets worse if we pose the question the other way round and ask “What suburb has postcode 2299?”.
In this case the answer of Lambton and North Lambton is correct, but New Lambton is incorrect! (It’s postcode is 2305)
So in the three examples preceding, how has Google AI Overview fared?
It provided a correct answer, but not to the question I was seeking an answer for.
It provided a correct but misleadingly incomplete answer.
It provided an incorrect answer.
Interestingly I tried the postcode queries on other devices and browsers, and the answers returned were not always the same, and sometimes the answer was correct. But regardless of whether the answer was correct, partially correct or totally incorrect – it was presented with the same level of confident self-assertive authority.
And that illustrates perfectly the essence of the AI Con, it is a confidence trick. It claims to deliver something (the answer) that it often does not deliver, and by design cannot deliver reliably. At the heart of this confidence trick is the “I” in “AI”, which is promising Intelligence where there is none.
A Large Language Model AI is just a machine with inputs and outputs. It takes inputs in the form of text training data, does lots of pattern matching, takes an input of text question, the internals of the machine spin around doing algorithmic pattern matching, and then it emits a text “answer” as the output. But there is no thinking involved, there is no meaningful analysis or comparison of alternative answers, there is no understanding of me as a person and my current state of knowledge, there is no real world human experience or plain common sense brought to bear in producing the answer. There is no intelligence. None. Zero.
It’s just like a mechanical sausage making machine, where you add inputs such as meat and spices, turn the handle, and the machine unthinkingly extrudes a sausage.
One of my favourite things I gained from Bender and Hanna’s book is their designation of large language model AI’s as “synthetic text extruding machines.” We wouldn’t describe a machine that extrudes sausages as “intelligent”, nor should we describe an algorithmic pattern matching machine that extrudes text as “intelligent”.
From now on I’m taking “AI” to stand for “Accelerated Ineptitude”.
While preparing a household budget today for the next calendar year, I was somewhat shocked to discover that my Microsoft M365 subscription for next year was jumping from $109 to $159, an increase of nearly 50%. A bit of research showed that the price jump was due to the introduction of AI capabilities (branded as Copilot) in the suite of Office products. I have no use for these AI functions, and was somewhat miffed that I was going to be slugged for features I’m never going to use.
The good news is that it is possible to revert back to an M365 subscription without the AI, and avoid the inflated price. The process to do this is slightly non-obvious. You have to …
Click the “Cancel subscription” link, which will then take you to page where you have the option to …
Choose the “Microsoft 365 Personal Classic” subscription (with no AI)
Just to demonstrate how pathetically useless AI is, I asked Microsoft’s Copilot to “generate an image of an evil corporation sucking money from unsuspecting consumers”, and this is all I got. 🙁
Here’s another weird issue in transitioning to the Lightning user interface in Salesforce.
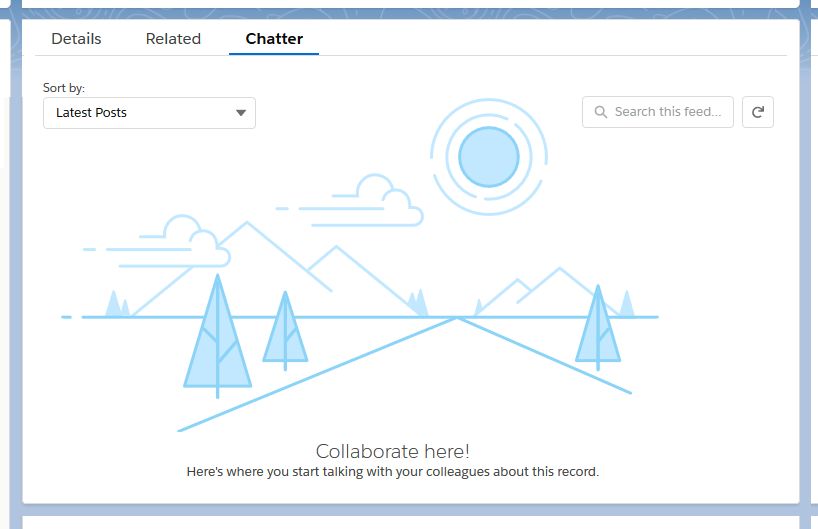
One of our users who regularly adds Chatter posts to records in the system, reported that they were unable to post a new Chatter thread against a record. On checking I likewise found that on the Chatter tab there was a bold invitation to “Collaborate here! Here’s where you start talking with your colleagues about this record.” But there was no way to actually post a message!
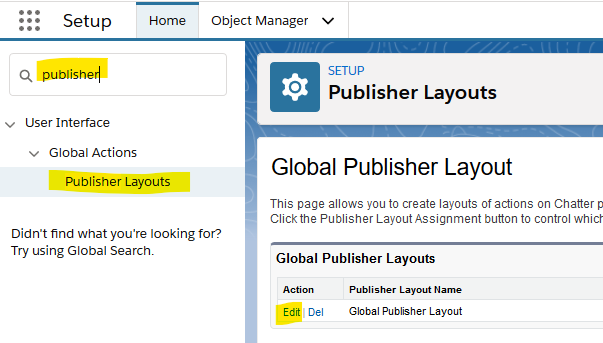
The issue turned out to lie with the Global Publisher Layout, which defines the actions that will be available for Chatter. From Setup search for “publisher”, click on “Publisher Layouts” and then edit the “Global Publisher Layout”
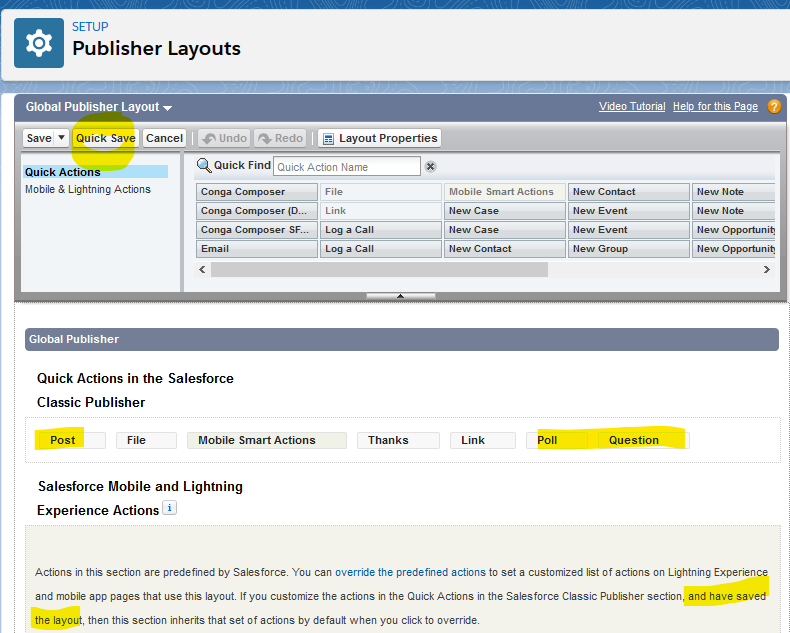
The “Classic Publisher” section defines what chatter actions will be available in the classic interface, and if no overrides are made in the “Lightning Experience Actions” section, then the Lightning interface should inherit the settings from the “Classic” section. However I found that it wasn’t until I saved the layout (without even making any changes) that the Chatter actions appeared in Lightning.
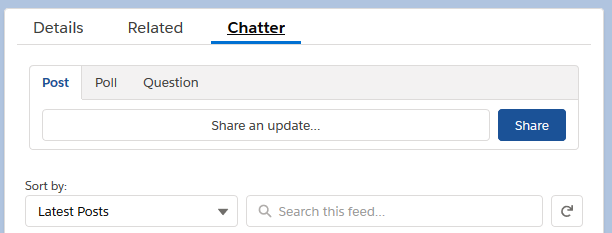
After clicking on “Quick Save”, the “Post”, “Poll” and “Question” actions appeared in the Chatter tab in the Lightning experience.
This post documents an obscure issue I discovered relating to the Salesforce Streaming API after switching to the new Lightning user interface.
For several years now at work we’ve had an integration that uses the Salesforce Streaming API to sync customer and contact information from Salesforce to an on-premise system. Recently after some users transitioned to the new Lightning user interface, the integration stopped working.
On investigation, it turned out to be related to field permissions. One of the fields configured in the PushTopic was a formula field. The permissions on this formula field were set to make it readable by only Administrators and the Integration user.
When using the Salesforce classic interface, if another user (who did not have read permission on the formula field) updated a record, the formula field value appeared in the streaming event
When using the Lightning interface, if another user (who did not have read permission on the formula field) updated a record, the formula field value did not appear in the streaming event.
As this formula field was a required value in our integration, the fact that it was missing caused the integration to break. The simple solution was to make this formula field readable by all users.
In summary, there seems to be a subtle change in the behaviour of the Streaming API between Classic and Lightning interfaces. The following is not an authoritative statement, but from my testing it appears that …
In the Classic interface, the fields available in the streaming event are determined by the permissions of the user subscribing to the PushTopic channel.
In Lightning, the fields available in the streaming event are determined by the permissions of the user generating the event.
This week at work I struggled with a Salesforce Flow that I was trying to delete, but couldn’t. It seemed to be a bit of a ‘zombie’ Flow, that was a little bit alive and a little bit dead. It all made sense in the end, but when I was in the middle of it all, it seemed inexplicable.
It started with a custom field that our company had added some time ago, which was no longer needed and I wanted to delete. On trying to delete the system wouldn’t let me, saying that it was in use by a Flow. I clicked on the “Where is this used?” button which identified that the field was referenced in a flow.
Clicking on the hyper link to the Flow, opened it in the Flow Builder, but that interface does not allow any way for the the Flow to be deleted.
So I went to the Setup interface, to the Flows menu item to delete it. But although the Flow clearly existed (I had it open in Flow Builder a moment ago) it wasn’t appearing in the “All Flows” list for me to delete.
Next, I thought I’d try to delete this zombie flow by using a metadata deployment. I use the Gearset tool for deployments, and by comparing a sandbox Org without the Flow to the one that had the Flow I generated a ‘delete’ type deployment … which then failed with the unhelpful error message “Insufficient access rights on cross-reference id”.
Eventually I figured out that the Flow couldn’t be deleted because it was referenced from a Process Builder. When I had located and deleted that Process Builder the ‘zombie’ Flow disappeared, and I was then able to delete the custom field. What made things tricky was that it wasn’t the latest active version of the Process Builder that referenced the Flow, but an earlier inactive version, so I had to search through all the earlier versions to identify the one that needed to be deleted.
The bottom line is that Salesforce won’t let you delete something that is referenced by some other design element. That’s a good thing. But the bad thing is that it can sometimes be hard (and non-obvious) finding what exactly is referencing the element you’re trying to delete.
This post is mostly a reminder to myself for the next time I need to do this …
For backing up files on my laptop running Window 10, I have an external USB hard drive permanently plugged in to my docking station at work. I then have backup software that runs backup jobs at scheduled times during the week. Recently I needed to upgrade to a larger capacity hard drive. With the purchase of a new hard drive, I also decided it was an opportune time to start using Microsoft’s BitLocker to encrypt the backed up files.
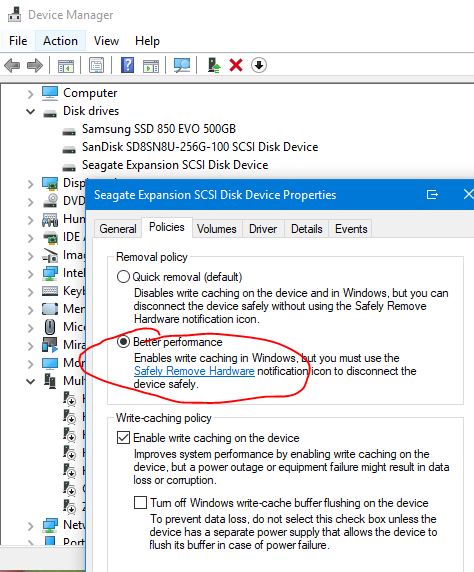
After plugging in the new drive and setting up BitLocker, I found that the backup performance was woeful. Backup jobs that used to take a few minutes were now taking hours. After a bit of experimentation and research, I found that the performance issue was nothing to do with BitLocker, but simply that I needed to enable write caching on the external drive.
The steps to achieve this were:
Open Windows Device Manager.
Locate the external drive in the list, right click and choose Properties.
Click on the Policies tab.
Change from the “Quick removal (default)” setting to the “Better performance” setting, to enable the write cache.
After doing this, backup jobs now ran in the same small amount of time as when I used the previous drive.
As a software developer I well know that software and information systems can have bugs. But it still astonishes me when software from big companies that is being used thousands of times each day across the world has egregious errors.
For example, look at this screenshot from the Malaysian Airlines iPhone app, where the top of the screen has a prominent and scary message about there being no e-mail address provided, while the bottom of the screen has a notification that an e-mail has just been sent to the address which is supposedly not available. And yes, an e-mail was received.













{kind=link}